자연어 처리(Natural Language Processing) 는 일상생활 속에서 사용하는 언어를 분석하여 분류하는 것을 목표로 합니다. 그 과정에서 자연스럽게 텍스트 분류(Text Classification) 과정을 진행합니다. 텍스트 분류는 문장, 문단 또는 글을 어떤 카테고리에 분류하는 작업입니다. Input으로 문장(Sentence) 혹은 문단(Paragraph)가 입력되고, Output으로 특정 카테고리를 출력합니다. 텍스트 분류의 예시는 다음과 같습니다.
- 감성 분석(Sentiment Analysis) : 트위터나 인스타그램 포스팅에 적혀진 글을 보고 긍정적인지, 부정적인지 판별합니다.
- 카테고리 분류(Text Categorization) : 영화 리뷰를 보고, 해당 영화가 어떠한 카테고리에 포함되는지 분류합니다.
- 의도 분류(Intent Classification) : 챗봇이 사용자의 의도를 파악하여 질의를 처리합니다.
Text Classification
텍스트 분류를 진행하기 위한 개괄적인 프로세스는 다음과 같습니다. 자연어 처리를 위한 데이터셋을 구축합니다. 데이터셋은 문장, 문단, 글로 구성될 수 있으며, 일반적으로 문장(Sentence)로 표현합니다. 이후, 데이터 전처리를 통해 데이터를 신경망에 적합한 형태로 변환합니다. 변환된 데이터는 신경망의 학습을 통해 정상적인 결과를 출력하게 됩니다.
- 데이터셋 구축
- 데이터 전처리 (Tokenization, Word Embedding, …)
- 모델 학습 및 결과 확인 (RNN, LSTM, Bi-LSTM, CRF, …)
Sentence Tokenization
먼저, 텍스트 분류를 진행하기 위해 문장($X$)이 주어집니다. 각 문장의 크기는 상이하며, 각 문장 $X$는 토큰(Token, $x_T$)들로 구성됩니다. 토큰은 문장을 구성하는 구성원이며, 각 토큰은 사전 정의된 단어장($V$)에 속한다고 가정합니다. 단어장은 영어로 Vocabulary 또는 Dictionary라고 표현하며, 컴퓨터가 이해할 수 있도록 단어를 숫자로 표현하도록 도와주는 역할을 수행합니다. 예를 들어, Location이라는 Vocabulary에는 Seoul, New York, London 등이 포함되어 있으며, 이는 1, 2, 3등의 Random Index로 Mapping 되어 있습니다.
토큰은 다양한 기준에 의해 구분될 수 있습니다. 공백, 형태소, 어절 등으로 구분될 수 있습니다. 만약 ‘자연어 처리를 위한 예시 문장입니다.’라는 문장이 들어왔을 때, 각 기준에 따라 토큰의 구성이 달라집니다.
- 공백(White Space) 기준 : (자연어, 처리를, 위한, 예시, 문장입니다, .)
- 형태소(Morphs) 기준 : (자연어, 처리, 를, 위한, 예시, 문장, 입니다, .)
- 어절 기준 : (자, 연, 어, [], 처, 리, 를, [], 위, 한, [], 예, 시, [], 문, 장, [], 입, 니, 다, .)
Token Encoding
토큰을 나누고, 각 토큰을 컴퓨터가 이해할 수 있도록 중복되지 않는 인덱스로 바꾸어줍니다. 이는 모든 토큰을 숫자화 하는 것으로, 궁극적으로 모든 문장을 Random한 일련의 정수들의 집합으로 변환합니다. 이를 인코딩(Encoding)이라고 합니다. 인코딩은 아래의 표와 같이 표현할 수 있습니다.
| Index | Token |
|---|---|
| … | … |
| 5 | 자연어 |
| 12 | 처리를 |
| 19 | 위한 |
| 21 | 예시 |
| 25 | 문장 |
| … | … |
| 38 | 입니다 |
One-hot Encoding
하지만, 이렇게 Random Index로 인코딩 하는 방식은 관계없는 숫자들을 나열하는 것으로, 단어 사이의 의미를 표현할 수 없다는 한계점이 존재합니다. 따라서, 이러한 관계성(Relationship)을 나타내기 위한 여러가지 방법들이 존재합니다. 대표적으로 원-핫 인코딩(One-hot Encoding) 을 사용한 방법이 있습니다. 원-핫 인코딩은 단어장의 총 길이($|V|$)인 벡터에서, 단어의 Index 위치에 있는 값은 1, 나머지는 0으로 구성합니다. 이는 아래의 그림을 통해 쉽게 이해할 수 있습니다.

위의 그림에서 Column은 단어장을 구성하는 워드 벡터이며, Rows는 Random Index로 Mapping된 토큰입니다. Rome이라는 토큰이 들어오면, Rome에 해당하는 Column을 제외한 나머지 Column들을 모두 0으로 변환합니다. 나머지도 동일한 로직에 의해 처리됩니다. 이를 수식으로 나타내면 다음과 같습니다.
\[x = [0, 0, 0, \dots, 0, 1, 0, \dots, 0] \in \{0, 1\}^{|V|}, \quad \sum_{i=1}^{|V|}x_i = 1\]Word Embedding
단순히 원-핫 인코딩을 진행하는 것만으로는 단어의 의미를 파악하기 어렵습니다. 이러한 상황을 타개하기 위한 방법으로 신경망을 사용합니다. 그렇다면 어떻게 신경망이 토큰의 의미를 파악할 수 있을까요? 결론적으로, 원-핫 인코딩된 토큰들을 연속 벡터 공간(Continuous Vector Space) 에 투영함으로써 가능합니다. 이를 워드 임베딩(Word Embedding) 이라고 합니다. 다시 말하면, 원-핫 인코딩된 토큰에게 벡터($x$)를 부여하여 연속 벡터 공간($W$)에 내적 한 것이라고 할 수 있습니다.
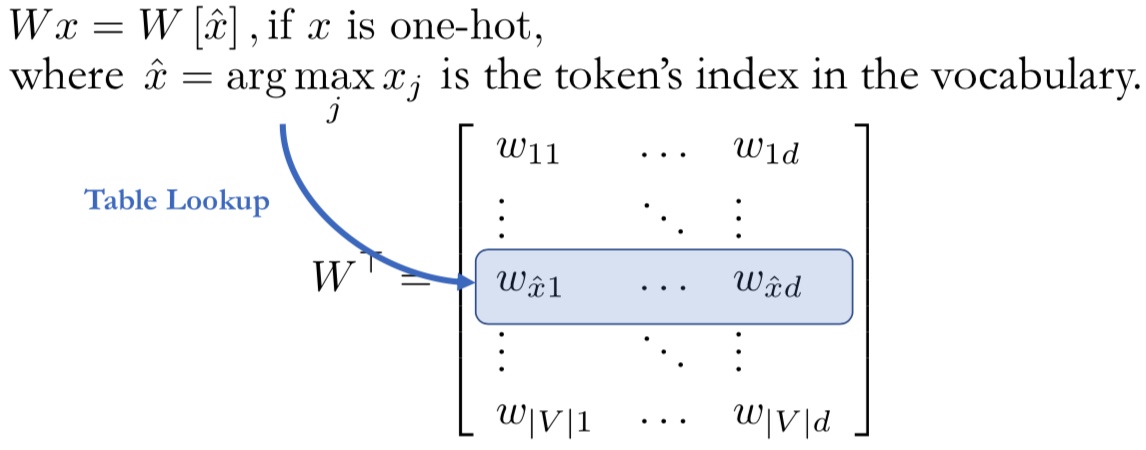
위와 같은 과정을 통해 모든 문장의 토큰들은 연속적이고 높은 차원의 벡터로 변환됩니다. 정리하자면, Input되는 문장들은 Sequence Vector로 변환되는 것이며, 각 벡터들은 각 토큰의 의미를 가지고 있습니다.
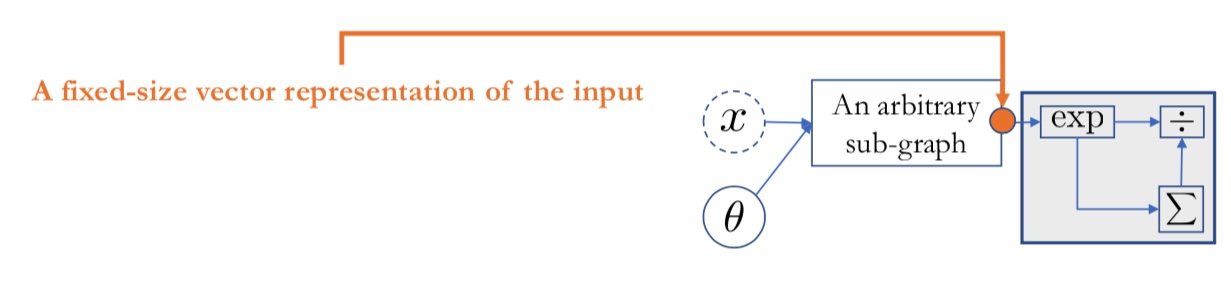
\[X = \{e_1, e_2, \dots, e_T\}, \quad where\ e_t \in \mathbb{R}^d\]결과적으로, 신경망 연산을 통해 산출된 벡터의 사이즈는 카테고리의 사이즈와 동일하며, Softmax Function을 통해 해당 토큰이 어떠한 카테고리에 속할지에 대한 확률(Probability)을 반환하게 됩니다.
References
Natural Language Proceesing Basic의 모든 포스팅은 뉴욕대 조경현 교수님의 ‘딥러닝을 이용한 자연어 처리’ MOOC 강의를 정리한 것입니다. (https://www.edwith.org/deepnlp/joinLectures/17363)